MarkTechPost
6/17/2026
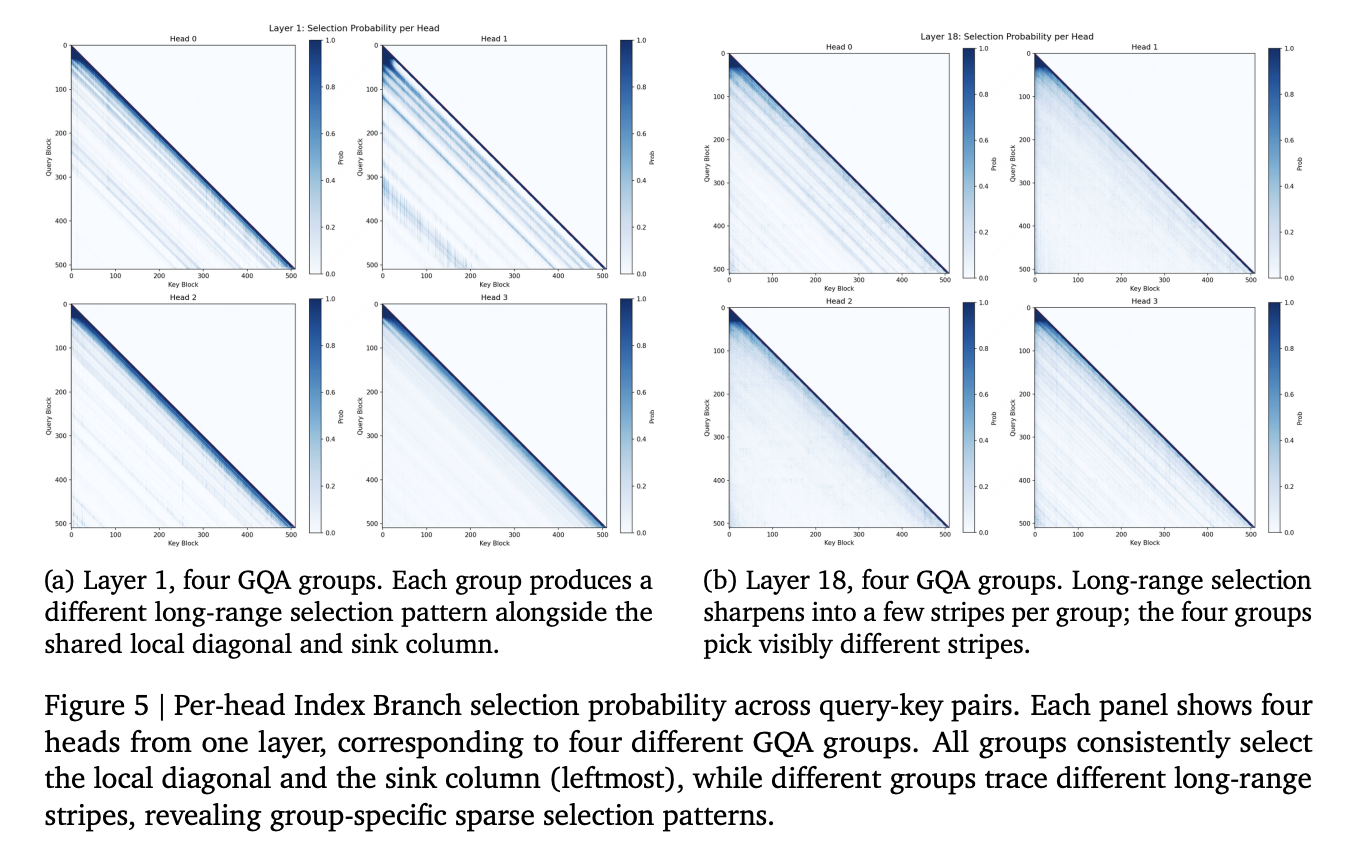
MiniMax Sparse Attention (MSA): a Two-Branch Block-Sparse Attention Trained on a 109B-Parameter MoE With a 3T-Token Budget
Short summary
MiniMax released MSA, a sparse attention mechanism reducing per-token compute 28.4× at 1M context while matching GQA performance. Two-branch architecture uses a lightweight Index Branch to select top-k key-value blocks, with the Main Branch attending only to those blocks, enabling massive efficiency gains.
- •28.4× reduction in per-token attention compute at 1M context
- •Two-branch sparse design built on Grouped Query Attention
- •Trained on 109B-parameter MoE with 3T-token budget
Generated with AI, which can make mistakes.
Is this a good recommendation for you?

