Dev.to
6/19/2026

Optimizing AI agent costs: A case study in token efficiency and model routing
Original: I Cut My AI Agent's Token Bill by 62% in One Weekend. Here's the Receipts.
Short summary
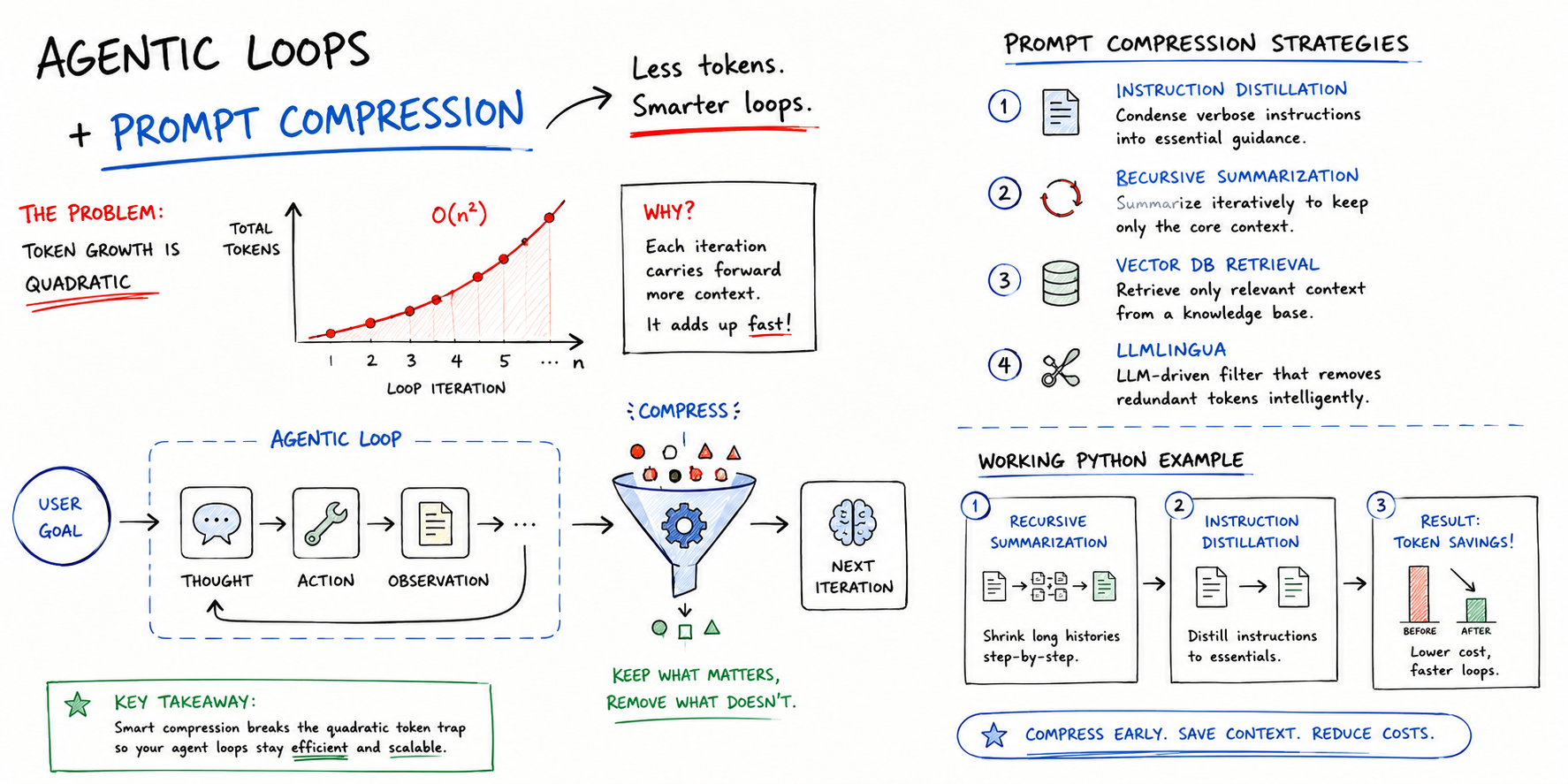
An engineer reduced AI agent costs by 62% ($5.40 → $2.05 per task) using context filtering (chunk-then-extract), system prompt pruning, and multi-model routing—reserving expensive reasoning models only for synthesis work. The approach improved citation coverage from 67% to 89% and reduced latency 32% while maintaining fact accuracy, proving that leaner context and targeted model choice outperforms brute-force context dumping.
- •Reduced per-task costs 62% through context filtering, prompt cleanup, and multi-model routing
- •Improved citation coverage from 67% to 89% and latency by 32% without sacrificing accuracy
- •Demonstrated that task-appropriate model selection beats always using the largest/most expensive model
Generated with AI, which can make mistakes.
Is this a good recommendation for you?